正好今天刚刷到新闻,xAI的估值已经到2000亿美元了,正式跻身世界LLM俱乐部前列。
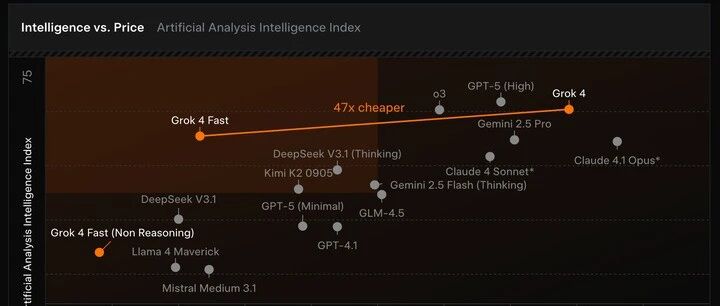
正好今天刚刷到新闻,xAI的估值已经到2000亿美元了,正式跻身世界LLM俱乐部前列。测试了一下Grok-4 Fast,明显快了很多,我让它介绍一下自己的特点,思维链 + Search工具调用,只思考了10s,首个token时延不到1s(919ms):相比之下,Grok 4 Expert模式,思考时间要两倍多,达到了24s,首token时延也接近两倍了,用了1.7s:明显这是一款高性价比的模型,主要用来普及Grok系列模型的用户使用率,从这张Intelligence vs. Price图表中可以一目了然看出来:横坐标是花费成本,纵坐标是智能intelligence水平,Grok 4 Fast相对于Grok 4 便宜了47倍
而且智能水平只是略微下降,所以从他们提供的数据上看,现在处于最高性价比的区域,对比的模型包括咱们熟悉的 GPT、Claude、DeepSeek、Kimi、Llama4等等。
Grok 4 Fast直接用端到端 tool-use RL训练的,实现"Native Tool Use",在LMArena Search Arena 这个搜索Benchmark上直接刷到了第一,超过了之前的SOTA o3-search。。还需要再补充一个大家可能会忽略但非常关键的特点,即Grok 4 Fast采用的是统一模型(Unified model)同时实现Reasoning and Non-Reasoning 切换,由系统提示词system prompt触发。此外还有几个亮点:
一是超大上下文窗口,支持2M个token,这个数量级就比较适合处理长文档、复杂对话或大规模数据分析。
二是支持多模态,在文本的基础上增加了图像和语音。
三是上面介绍的输出速度和成本优势。
当然,最大的亮点是可以免费使用,在香港IP是可以直接访问的。
之前Grok 4成本太高,免费额度很少。估计订阅用户数量也不多,这下Grok 4 Fast模型正好填补了这一空白。



没有评论:
发表评论